
Are you puzzled by Unicode? You’re not alone! At Lingoport, we’ve noticed that many clients and friends have varying degrees of familiarity with Unicode, from complete beginners to those who just need a quick refresher.
Understanding Unicode is critical for anyone involved in creating global software applications and websites. It allows your projects to support a diverse range of language scripts worldwide. This guide will explain what Unicode is and why it’s indispensable for successful internationalization.
What is Unicode?
Unicode is a character set standard used for displaying and processing language data in computer applications. It encompasses the entire world’s set of characters, including:
- Letters
- Numbers
- Currencies
- Symbols
The Basics of Character Encoding
To understand Unicode, it’s essential to grasp the concept of character encoding:
- Computers represent all information in binary (zeros and ones).
- Character encoding maps these binary values to specific characters.
- For example, in ASCII, the letter ‘A’ is represented as 1000001 (7 bits).
The Evolution of Character Encoding
ASCII: The Beginning
ASCII (American Standard Code for Information Interchange) was the early standard for character encoding:
- Used 7 bits per character
- Limited to 128 characters
- Insufficient for representing non-English alphabets and complex scripts
- Localization Considerations:
- Use Case: Primarily used for English text.
- Limitations: Insufficient for languages with accented characters, and not usable for languages with non-Latin scripts.
Impact: Not suitable for global applications as it lacks support for international character sets.
The Challenges of Single-Byte and Double-Byte Encodings
To support non-English languages, various single-byte (8-bit) and double-byte (16-bit) encodings were developed:
- Single-byte encodings: Supported European languages with accented characters
- Double-byte encodings: Required for complex scripts like Chinese, Japanese, and Korean
The Problem: This approach led to multiple versions of software for different languages, resulting in:
- Increased development costs
- Difficult maintenance
- Inconsistencies across language versions
ISO Latin: A Partial Solution
ISO Latin 1 (International Organization for Standardization 8859 Series) was developed to support Western European languages:
- Character Range: Each set in the series supports up to 256 characters, designed for different language groups (e.g., ISO-8859-1 for Western European languages, ISO-8859-5 for Cyrillic scripts).
- Localization Considerations:
- Use Case: Useful for languages within the specific region each variant covers.
- Limitations: Each set is limited to a small subset of languages and can’t be mixed in a single document without switching encodings.
Impact: Limited use in modern applications where a single universal character set is preferable.
Enter Unicode: The Global Standard
Unicode was created to support any written language worldwide, offering several advantages:
- Universal character set
- Supports almost all scripts
- Eliminates the need for multiple language-specific versions of software
Unicode supports multiple encodings, each with its own characteristics. Let’s explore them:
UTF-8
- Full Name: 8-bit Unicode Transformation Format
- Character Range: Supports all characters in the Unicode standard using one to four bytes per character.
- Localization Considerations:
- Use Case: Universally accepted and used for any language in the world, making it highly flexible and widely supported.
- Advantages: ASCII-compatible, making it backward-compatible for most existing content encoded in ASCII.
Impact: Ideal for web content and global software development due to its flexibility and efficiency in handling multilingual text, especially when memory and bandwidth are considerations. Commonly used on UNIX platforms and web content.
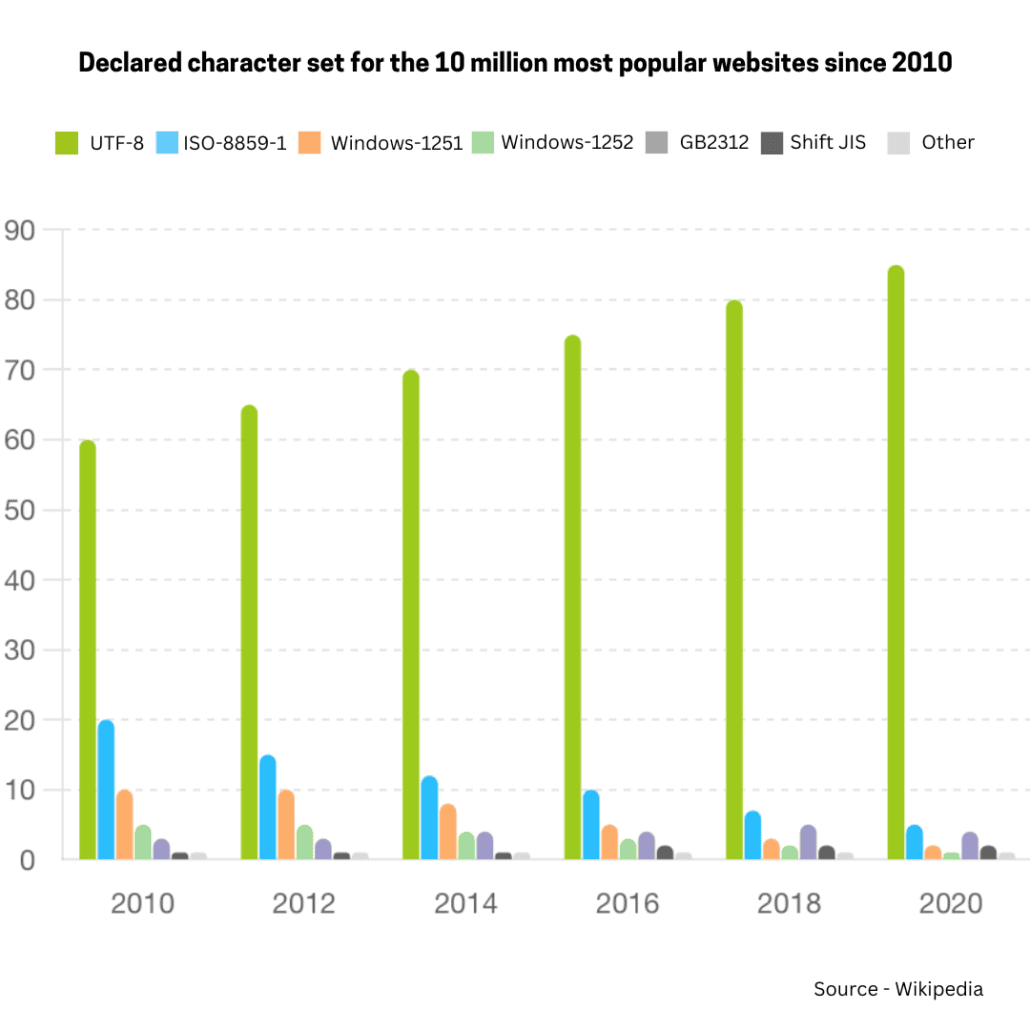
UTF-8 has been the most common encoding for the World Wide Web since 2008. As of October 2024, UTF-8 is used by 98.3% of surveyed web sites.Although many pages only use ASCII characters to display content, very few websites now declare their encoding to only be ASCII instead of UTF-8. Over 50% of the languages tracked have 100% UTF-8 use.
UTF-16
- Full Name: 16-bit Unicode Transformation Format
- Character Range: Uses two bytes for the majority of characters but can use four bytes for characters outside the Basic Multilingual Plane (BMP).
- Localization Considerations:
- Use Case: Commonly used in environments like Java and .NET, where it’s the default character encoding.
- Advantages: Efficient for languages with characters that typically require two bytes, like many Asian scripts. Used internally by Java and .NET for string processing
- Limitations: Less space-efficient than UTF-8 when handling languages that primarily use the Latin script.
Impact: Suitable for applications where consistent character size is beneficial, such as in certain database and programming environments.
UTF-32
- Full Name: 32-bit Unicode Transformation Format
- Character Range: Uses four bytes for all characters, providing a fixed width for every character in Unicode.
- Localization Considerations:
- Use Case: Useful in specific computational or scientific applications where fixed-width characters simplify character handling.
- Advantages: Simplifies processing since every character has the same width.
- Limitations: Inefficient in terms of memory use, especially for texts primarily using Latin characters.
Impact: Not widely used in general applications due to its high space requirements.
UCS-2
- Similar to UTF-16 but without 4-byte character support
- Used by Microsoft SQL Server
GB 18030: The Chinese Standard
A Chinese government standard, mandatory for software sold in China.
- Character Range: A superset of Unicode, supports all characters defined in Unicode and additional Chinese characters.
- Localization Considerations:
- Use Case: Essential for software targeting the Chinese market to comply with Chinese regulations.
- Advantages: Supports both simplified and traditional Chinese
Impact: Ensures software products can be legally sold and used in China, covering all necessary character sets for comprehensive Chinese language support.

Each character encoding has its specific use cases and implications for localization. UTF-8 is generally the most versatile and widely used, making it an excellent choice for most modern applications requiring international support. However, the choice of encoding can depend on specific language requirements, memory constraints, and computational efficiencies desired for the project.
Benefits of Unicode Support
If you choose Unicode for your character encoding you will get a multitude of benefits, especially when dealing with internationalization and localization of software and web content. Here are some key advantages:
Universal Character Set
Unicode covers virtually all scripts in use around the world, enabling the representation of text from multiple languages all within a single character set. This universality means you can handle diverse languages—ranging from the most widely spoken to lesser-used ones—all in the same document or software application.
Simplifies Development
Using Unicode simplifies the development process as developers need no switch between different encoding systems for different languages. This uniformity eliminates many of the complexities associated with multi-language support, reducing bugs and improving software maintainability.
Consistency Across Platforms
Unicode is supported and consistent across all major operating systems, databases, and programming languages. This consistency ensures that a Unicode-encoded text viewed on one system will appear the same on another, facilitating easier data exchange and integration.
Backward Compatibility
UTF-8, a method of encoding Unicode characters, is backward compatible with ASCII. This means that software and systems designed to use ASCII can often use UTF-8 without modification, making the transition smoother and less costly.
Efficient Use of Space
UTF-8 is particularly efficient for texts predominantly in English, as it uses only one byte per character for all standard ASCII characters, while still being able to support all other Unicode characters using 2 to 4 bytes as needed. This space efficiency makes UTF-8 very popular on the web and in other network-connected applications.
Supports Globalization
For businesses looking to operate globally, Unicode is almost essential as it supports almost all characters used in international communication. This support helps companies engage with a global customer base more effectively and ensures that brand messaging is consistent across different languages.
Future-Proof
As a comprehensive character encoding standard that is continuously updated, Unicode accommodates new characters and scripts as they evolve. This makes Unicode future-proof, supporting technological and cultural developments without the need for replacing the encoding system.
Improves Accessibility
Unicode supports the inclusion of various symbols, including those used in non-text elements like emojis, mathematical symbols, and icons, which play a crucial role in modern digital communication. This variety enhances the expressiveness and accessibility of written content across different media.
Legal and Compliance Benefits
In some regions, like China with its GB 18030 standard (a superset of Unicode), using Unicode is essential to meet legal and regulatory requirements for software products. Compliance with such standards ensures that products can be sold and used in these markets.
Reduces Costs
By adopting a single encoding standard, organizations can reduce the costs associated with developing and maintaining multilingual software, training staff in multiple encoding standards, and converting between different encodings.
As you see, the broad acceptance and versatility of Unicode make it an excellent choice for any application that requires handling multiple languages or special character sets. Its adoption is a critical step for any business aiming to operate on a global scale.

Conclusion
Unicode is essential for creating truly global software applications. By understanding and implementing Unicode support, developers can ensure their applications are ready to take on the world, providing a seamless experience for users across different languages and scripts.
Lingoport offers solutions that can help automate and streamline your i18n and l10n processes, ensuring your software is ready for global markets. If you need any support contact us. We can help you go global at the speed of development.




